在来自高通的一位大佬同学的建议下,我还是决定将IC验证的学习提上日程,嗯,,为找到工作献出心脏
verilog基础部分
概念
带着问题来看:
什么是硬件描述语言,它的主要作用?
一种用形式化方法来描述数字电路和系统的语言。设计者可以从上层到下层逐层描述自己的设计思想,用一系列分层次的模块来表示极其复杂的数字系统。
应用于设计的各个阶段:建模,仿真,验证和综合
采用硬件描述语言设计方法的优点是什么?有什么缺点?
传统设计方法——电路原理图输入法
手工布线,需要专门的设计工具,工作复杂且耗时较长。
采用HDL可以很容易的把完成的设计一直到不同厂家的不同芯片中,并在不同规模的应用中较容易的修改,来适应不同规模的应用。
最大的优点:是其与工艺无关性。这使得工程师在功能设计、逻辑验证阶段,可以不必过多考虑门级及工艺实现的具体细节。只需要利用系统设计时对芯片的要求,施加不同的约束条件,即可设计出实际电路。实际上是在EDA工具的帮助下,把逻辑验证与具体工艺库匹配,布线及时延计算分成不同的阶段来实现。
缺点:设计抽象层级高,底层基础不扎实可能会出问题
硬件描述语言可以用哪两种方式参与复杂数字电路的设计
HDL设计和验证
用硬件描述语言设计的数字系统需要经过那些步骤才能与具体的电路相对应
编写设计文件-功能仿真-优化、布局布线-布线后门级仿真
概念解释:IP? 软核?硬核?固核?虚拟器件?
IP:Intellectual Property(知识产权)
软核:把功能经过验证的、可综合的、实现后电路结构总门数在5000门以上的VerilogHDL模型称之为软核(soft core)
虚拟器件:由软核构成的器件
软核和虚拟器件可以很容易的借助EDA综合工具与其他外部逻辑结合为一体,其重用性可以大大缩短设计周期。
固核:把某一种现场可编辑门阵列(FPGA)器件上实现的、经验证是正确的,总门数在5000门以上的电路结构编码文件称为“固核”(firm core)
硬核:把在某一种专用集成电路工艺(ASIC)的器件上实现的,经验证是正确的,总门数在5000门以上的电路结构版图掩膜称为“硬核”(hard core)
Top_Down设计方法和HDL的关系
自顶向下的设计是从系统级开始,把系统划分为基本单元,然后再把每个基本单元划分为下一层次的基本单元,一直这样做下去,直到可以直接用EDA元件库中的基本元件来实现为止。
1. 语法的基本概念
1.1 概述
模块:HDL描述的电路设计就是该电路的verilog HDL模型,也称为模块
既描述行为,又描述结构
verilog模型可以是实际电路的不同级别的抽象。
- 系统级:用语言提供的高级结构能够实现带设计模块的外部性能的模型;
- 算法级:用语言提供的高级结构能够实现算法运行的模型
- RTL级:描述数据在寄存器之间的流动和如何处理、控制这些数据流动的模型
以上为行为描述,RTL级和逻辑电路有明确的对应关系
- 门级:描述逻辑门及其之间的链接
- 开关级:器件中三极管和存储节点以及他们之间链接的模型
1.2 模块的基本概念
1 | //二选一数据选择器 |
- always @(sl or a or b)表示只要sl或a 或 b,其中若有一个变化时就执行块内语句。
- 布尔表达式中的与或非分别为:”&”,”|“,“~”
书上的例2.1和例2.2在我看来,代表了描述电路的两种抽象层级。只考虑输入输出的关系和考虑中间过程。
而前两者和2.3 相比又有了注重行为和注重结构两种区别。
- u1,u2,u3,u4对应逻辑图中的逻辑元件(引用实例门模块),#1和#2分别表示们输入到输出的延迟为1和2个单位时间
- assign对应定义行为
- 在符合语法和基本规则的基础上,2.1可以通过2.2自动转换为2.3,这个过程叫综合。毕竟2.3和实际结构相对应,可通过布局布线工具自动的转变为某种具体工艺的电路布线结构。
- 实例引用:在trist2模块中所用到的三台驱动器元件bufif1的具体名字叫做mybuf,这种引用现成元件或模块的做法叫做实例化或实例引用。
- 模块中调用定义好的模块:在上层模块调用下层模块的实例部件中:带“.”表示引用模块的端口,名称必须与被引用模块的端口定义一致,小括号中表示在本模块中与之连接的线路。
1.3 verilog用于模块测试
测试模块可以对被测模块进行逐步深入的完整测试:
- 前(RTL)仿真:在功能(即行为)级上进行
- 逻辑网表仿真:在逻辑网表(逻辑布尔表达式)上进行
- 门级仿真:在门级结构级进行
- 布线后仿真:门级结构模块和具体工艺技术
2. 模块的结构、数据类型、变量和基本运算符号
2.1 模块的结构
verilog结构位于module和endmodule之间,每个verilog程序包括4个主要部分:端口定义,I/O说明,内部信号声明,功能定义
模块的端口定义
格式:module 模块名(口1,口2,口3,口4.。。。。);
- 模块的端口表示的是模块的输入和输出口名,即他与别的模块联系端口的标识
被引用时,在引用的模块中,有些信号要输入到被引用的模块中,有的信号要从被引用的模块中取出。
模块被引用时的取名规范:
模块名 (连接端口1信号名,连接端口2信号名,连接端口3信号名….);
模块名 (.端口1名(连接端口1信号名),.端口2名(连接端口2信号名),.端口3名(连接端口3信号名)…..)
模块内容
模块的内容包括I/O说明,内部信号声明和功能定义。
I/O说明的格式
输入口:input[信号位宽-1:0] 端口名1;
输出口:output[信号位宽-1:0] 端口名1;
输入输出口:inout[信号位宽-1:0] 端口名1;(双向总线端口)
内部信号说明
在模块内用到的和与端口有关的wire和reg类型变量的声明
功能定义-模块中最重要的部分
(1)assign声明:assign a = b&c
(2)实例元件:and #2 u1(q,a,b)
(3)用“always”块:如:always @(posedge clk or posedge clr);
begin
if(clr) q<=0;
else if(en) q<=d;
end
注意:
- assign语句常用于描述组合逻辑,而“always”块既可以用于描述组合逻辑,也可描述时序逻辑。
- 一个模块中的assign语句,实例元件,always块的逻辑功能是同时执行的,也就是并发的;而always块内的语句是顺序执行的。
与软件的很大不同:
verilog中的所有过程块(initial,always),连续赋值语句assign,实例引用都是并行的
个人理解:功能部分的每个块都是并行的,该延迟的会用“#2”代表延迟时间。
表示的是一种通过变量名互相连接的过程
三者的先后次序无关
只有连续赋值语句assign,实例引用能独立于过程块而存在于模块的功能定义部分
2.2 数据类型及其常量和变量
verilog的数据类型共19种,4个最基本的数据类型:reg,wire,integer,parameter
其他类型:large型,scalared型,time型,small型,tri型,trio型,tril型,triand型,trior型,trireg型,vectored型,wand型,wor型。
2.2.1 常量
在程序运行过程中,值不能被改变的量被称为常量
数字型常量
整数常量的进制表示
(1)二进制整数(b或B)
(2)十进制整数(d或D)
(3)十六进制整数(h或H)
(4)八进制整数(o或O)
数字表达
(1)<位宽><进制><数字>
(2)<进制><数字>:数字位宽为默认值,机器系统决定,至少32位
(3)<数字>:采用默认进制10进制
注意:4位二进制的数字位宽为4,4位16进制的位宽为16。8’b10101100;;;;;;;8’ha2
x和z(不定和高阻)值的表示
注意:z可以用?来表示
负数
注意:“-”必须写在位宽的前面
下划线
下划线可以用来分隔开数的表达以提高程序可读性。只能用于数字
当常量不说明位数时,默认值是32,每个字母用8位的ASCII值表示
参数(parameter)型常量
用parameter来定义一个标识符代表一个常量,即符号常量。
使用方式:
parameter 参数名1=表达式,参数名2=表达式,参数名3=表达式;
每个赋值语句的右边必须是一个常数表达式。也就是说该表达式只能包含数字或先前已经定义过的参数。
1
parameter byte_size = 8, byte_msb = byte_size-1;
使用场合:
定义延迟时间和变量宽度。在模块或实例引用时,可通过参数传递改变在被引用模块或实例中已定义的参数。可以使得已编写的底层模块具有更大的灵活性。
2.2.2 变量
网络数据类型表示结构实体之间的物理连接。
wire型变量
默认初始值是z
wire型数据一般表示用以assign关键字指定的组合逻辑信号。verilog程序模块中输入,输出信号类型默认时自动定义为wire型,wire型信号可以用作任何方程式的输入,也可以用作assign语句或实例元件的输出。
可综合为连线
1
2wire [4:1] c,d; //定义了两个4位的wire型数据
wire [3:0] b; //定义了1个4位的wire型数据reg型变量
默认初始值是x
寄存器是数据存储单元的抽象。寄存器数据类型的关键字是reg。通过赋值语句可以改变寄存器存储的值,其作用与改变触发器存储的值相当。
reg类型数据不一定综合为寄存器,在纯组合逻辑中,综合和实现结果不会使用FF
注意:
- reg型数据常用来表示“always”模块内的指定信号,常代表触发器。在“always”模块内被赋值的每个信号都必须被定义为reg型。
- 当一个reg型数据是一个表达式中的操作数时,它的值被当做是无符号,即正值(补码)。
memory型变量
通过对reg类型变量建立数组来对存储器建模,可以描述RAM型存储器、ROM存储器和reg文件。数组中的每个单元通过一个数组索引进行寻址。因为verilog语言没有多维数组存在,memory类型数据通过扩展reg类型数据的地址范围来生成。
1
reg [n-1:0] 存储器名 [m-1:0] //[m-1:0]表示有m个n位的寄存器,,存储器的地址范围即0到m
通过parameter同时定义存储器型数据和reg型数据
1
2parameter wordsize = 16, memsize = 256;
reg[wordsize-1:0] mem[memsize-1:0],writereg,readreg;注意:
如果想对memory中的存储单元(单个寄存器)进行读写操作,必须指定该单元在存储器中的地址。
1
mem[3] = 0; //3即索引地址
进行寻址的地址索引可以是表达式,而表达式的值可以取决于电路中其他寄存器的值。如果用一个加法计数器来做RAM的地址索引,不就可以实现循环访问吗!
2.3 有符号数和无符号数
常量:
普通十进制数一律被认为是有符号数,如:
32 //有符号数;
-15 //有符号数;
基数格式表示情况下,数的符号要明确声明,如:
1
28'sh51 //8位有符号数01010001;
6'so72 //6位有符号数111010,即十进制数下的-6 ;对于未声明符号位的,按无符号数处理:
1
24'd2 //4位无符号数
'hAF //32位16进制数,无符号。注意未声明长度的,统一按32位长度处理
变量:
当将一个常数赋值给某个变量时,仿真器如何解释这个常数的值,最终取决于这个变量的符号形式,此时常数的符号仅仅决定常数的各位取1还是0而已。
将一个有符号常量赋值给一个无符号变量可能会出现意想不到的结果。
2.3 运算符及表达式
需要注意的有:位运算符(~,|,^,&,^~),拼接运算符({ })。
在进行整数除法运算时,结果值要略去小数部分,只取整数部分;取模运算结果值的符号位和第一个操作数的符号位相同
位运算符
^:异或
^~:同或
注意:
不同长度的数据进行位运算,系统会自动的将两者按右端对齐,位数少的操作数会在相应的高位用0填满。
3. 运算符、赋值语句和结构说明语句
3.1 逻辑运算符
&& , || , !,区别于位运算符,操作数为布尔类型的表达式。
注意:两个双目运算符(“&&”,“||”)的优先级低于关系运算符,“!”高于算数运算符
3.2 关系运算符
关系运算符的优先级低于算数运算符
如果声明的关系是假的,返回0,是真则返回1。
1 | size-(1<a) |
3.3 等式运算符
区别于软件:==;!=;===;!==
由于操作数中某些位可能是不定值x和高阻值z,结果可能为不定值x。而“===”,“!==”又称为运算符不同,它对操作符进行比较时对某些位的不定值x和高阻值z也进行比较,两个操作数必须完全一样,结果才是1,否则为0。
===;!==运算符常用于case表达式的判别,所以又称为“case等式运算符”。
3.4 移位运算符
3.5 位拼接运算符
可以把两个或多个信号的某些位拼接起来进行运算操作。
{信号1的某几位,信号2的某几位,。。。}
1 | {a,b[3:0],w,3'b101} |
注意:不允许存在没有指明位数的信号
特殊用法
重复法来简化表达
{4{w}}
位拼接还可以用嵌套的方式来表达
{b,{3{a,b}}}
3.6 缩减运算符
单目运算符,类似于位运算符,缩减运算是对单个操作数进行或,与,非递推运算,最后的运算结果是1位的二进制数。
- 运算过程
- 先将操作数的第1位与第2位进行或,与,非,运算
- 再与第3位进行该运算
- 直至最后一位
3.7 赋值语句和块语句
3.7.1 赋值语句
信号赋值的两种方式
非阻塞(Non_Blocking)赋值方式(如b<=a;)
看似与关系运算符长的一样,但意义完全不同
(1)语句块中,上面语句所赋的变量值不能立即就为下面的语句所用
(2)块结束后才能完成这次赋值操作,而所赋的变量值是上一次赋值得到的
(3)在编写可综合的时序逻辑模块时,这是最常用的赋值方法
(4)非阻塞赋值一定会综合出寄存器(存放中间值)
阻塞(Blocking)赋值方式(b= a;)
(1)赋值语句执行完后,块才结束;
(2)b的值是在赋值语句执行完后立刻就改变的;
(3)时序逻辑中,可能会产生意想不到的结果。
可以想象两个D触发器,触发器1的输出是2的输入,这里就只能使用非阻塞赋值。
3.7.2 块语句
- begin_end语句:标识顺序执行的语句,标识的块称为顺序块
fork_join语句:标识并行执行的语句,标识的块称为并行块
顺序块:
- 每条语句的延迟时间是相对于前一条语句的仿真时间而言的
- 直到最后一条语句执行完,程序流程控制才跳出该语句块
- 并行块:
- 每条语句的延迟时间是相对于程序流程控制进入到块内的仿真时间而言的
- 延迟时间是用来给赋值语句提供执行时序的
- 当按时间时序排序在最后的语句执行完后或一个disable语句执行时, 程序流程控制跳出该程序块
1 | parameter d = 50; |
1 | fork |
以上两种方法产生的波形是一样的
块名
如何给块起名字
将名字加在关键词begin或fork后面
这么做的原因
(1)在块内部可以定义局部变量,即只在块内使用的变量
(2)命名块是设计层次的一部分,命名块中声明的变量可以通过层次名引用进行访问
(3)命名块可以被禁用,例如停止其执行
块语句的特点:
嵌套块:顺序块和并行块可以混合,相互嵌套使用
命名块:见上面
命名块的禁用——disable
非常类似使用break退出循环,区别在于break只能退出当前所在的循环,而disable可以禁用设备任意一个命名块。
1
2
3
4
5
6
7begin: block1
...;
begin
...;
disable block1;
end
end
又多了一个给块命名的作用!
4. 条件语句、循环语句、生成语句
4.1 条件语句(if/else)
**注意:条件语句必须在过程块语句中使用。即由initial和always语句引导的执行语句集合。除这两种块语句引导的begin_end块中可以编写条件语句外,模块中其他地方都不能编写。**3种形式:
1
2
3
4
5
6
7
8
9
10
11(1)if(a>b)
out1=int1;
(2)if(a>b)
out1=int1;
else
out1=int2;
(3)if(表达式)
语句1;
else if(表达式2) 语句2;
else if(表达式3) 语句3;
else 语句4;3点说明
在if和else后面可以包含一个内嵌的操作语句,也可以有多个操作语句,此时用begin_end这两个关键词将几个语句包含起来成为一个复合块语句。
允许一定程度的表达式简写(同软件)
1
2
3
4if(a==1)//可以表示为
if(a)
if(a!=1)//可以表示为
if(!a)if_else的配对关系,else总是与它上面的最近if配对。但是也可以使用begin_end块将if语句隔离
4.2 case语句
多分支选择语句,通常用于微处理器的指令译码
表示形式
1
2
3case(表达式) <case分支项> endcase
casez(表达式) <case分支项> endcase
casex(表达式) <case分支项> endcasecase分支项的一般格式为:
分支表达式:语句
默认项(default):语句
case括号中的表达式为控制表达式,通常表示为控制信号的某些位;
case分支项中的表达式为常量表达式,表示控制信号的具体状态值;
case语句的所有表达式值的位宽必须相等(不同于位运算符,不能自动补0)
很明显,与if_else语句相比,多了对z和x状态的处理
casez用来处理不考虑高阻值的z的比较过程,casex将高阻值z和不定值x都视为不关心的情况。
case语句的行为类似多路选择器,使用case语句可以很容易的构建
1 | //实现四选一多路选择器 |
为了避免出现锁存器的情况,if语句跟else,case语句配default分支。

4.3 循环语句
4种类型
for
forever:连续的执行语句
- repeat:连续执行一条语句n次
- while:执行一条语句直到某个条件不满足。(同软件)
for:3个步骤决定(同软件,但是控制变量必须是提前声明的或引用的寄存器变量)
例:将100位输入值的,全部位进行翻转后输出
1
2
3
4
5
6
7
8
9
10
11module top_module(
input [99:0] in;
output [99:0] out;
);
always @ (*) begin
integer i;
for(i=0; i<100; i=i+1) begin
out[99-i] = in[i];
end
end
endmodule注意!!!:
- 变量
i的声明 - always块中使用for循环
- i=i+1,不能写成i++
- 变量
forever:
1
2forever 语句;
forever begin 多条语句; endforever循环语句常用于产生周期波形,用于仿真测试信号。与always语句的不同之处在于不能独立写在程序中,必须写在initial块中。
repeat:
1
2
3repeat(表达式) 语句;
repeat(表达式) begin 多条语句; end
//repeat后面跟的表达式通常为常量表达式,代表循环次数以乘法计数器为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16parameter size = 8, longsize= 16;
reg[size:1] opa,opb;
reg[longsize:1] result;
begin: mult
reg[longsize:1] shift_opa,shift_opb;
shift_opa = opa;
shift_opb = opb;
result = 0;
repeat(size)
begin
if(shift_opb[1])
result = result + shift_opa;
shift_opa = shift_opa<<1;
shift_opb = shift_opb>>1;
end
endwhile:
表达方式与上面的相同
计数一个8位二进制数中有多少位1:
1
2
3
4
5
6
7
8
9
10
11//计数一个8位二进制数中有多少位1
begin: count1s
reg[7:0] tempreg;
count = 0;
tempreg = rega;
while(tempreg)
begin
if(tempreg[0]) count = count+1;
tempreg = tempreg >>1;
end
endfor:
循环变量增值表达式可以不必是一般的常规加法或减法表达式
以上面的二进制数中1的位数为例:
1
2
3
4
5
6
7begin: count1s
reg[7:0] tempreg;
count=0;
for(tempreg = rega; tempreg; tempreg>>1)
if(tempreg[0])
count = count+1;
end
4.4 生成语句
generate——endgenerate
- 作用:动态生成代码,提高码农效率
- 使用场景:
- 对矢量中的多个位进行重复操作
- 多个模块实例引用的重复操作
- 根据参数定义来确定是否应该包括某段verilog代码
应用对象:
- 模块
- 用户定义原语
- 门级原语
- 连续赋值语句
- initial和always块
三类语句和生成语句的区别(暂时理解):
一般的条件和循环语句只能对语句和块生效,对于上面所提到的应用对象,就需要这里的生成语句了。
5. 结构语句、系统任务、函数语句、显示系统任务
5.1 结构说明语句
verilog语言中的任何过程模块都从属于以下四种:
- initial说明语句
- always说明语句
- task说明语句
- function说明语句
可以有多个initial和always过程块。每个initial和always说明语句在仿真的一开始同时立即执行。initial语句只执行一次,always语句不断重复活动,直到程序仿真结束。
5.1.1 initial语句
一个模块中可以有多个initial块,且都是并行的。
常用于测试文件和虚拟模块的编写,用来产生仿真测试信号和设置信号记录等仿真环境
1
2
3
4
5
6
7
8//用initial语句产生激励波形
initial
begin
inputs = 'b000000;
#10 inputs = 'b011001;
#10 inputs = 'b011000;
#10 inputs = 'b001000;
end
5.1.2 always语句
always语句可以理解为对边沿或电平敏感的监视器!!!
always语句的声明格式:always <时序控制> <语句>
- always语句由于不断活动的特性,只有和一定的时序控制结合在一起才有用,如果没有时序控制,这个always语句将会使仿真器产生死锁。
- 根据触发条件判断是否执行
1 | reg[7:0] counter; |
对于多个信号触发的,中间用关键字or进行连接,也可以用“,”代替
沿触发的always块常描述时序行为,而电平触发的always块常用来描述组合逻辑行为
多个always块并行执行,无前后之分
@*,@(*)都表示对其后面语句块中所有输入变量的变化是敏感的另一种触发形式:wait关键字
1
2always
wait(count_enable) #20 count=count+1;
5.2 task 和 function说明语句
task和function分别用来定义任务和函数,和软件中函数的应用类似,为了将程序拆分为小的模块,增强代码复用性。
5.2.1 两者的区别
- 函数与主模块只能共用一个仿真时间单位,而任务可以定义自己的仿真时间单位
- 函数可调用函数但不能启动任务,任务可以启动其他任务和函数
- 函数至少要有一个输入变量,而任务可以没有或有多个任何类型的变量
- 函数返回一个值,任务不返回值
1 | //例如:定义一个任何或函数对一个16位的字进行操作,让高字节和低字节互换,把它变为一个字(假设任务或函数名为:switch_bytes) |
5.2.2 task说明语句
如果传给任务的变量值,任务完成后接收结果的变量已定义,就可以用一条语句启动任务,任务完成后控制就传回启动过程。如果任务内部有定时控制,则启动时间可以与控制返回的时间不同。
任务可以不断的嵌套启动下去,只有当所有的启动任务完成后,控制才能返回。
任务的定义:
1
2
3
4
5
6
7
8
9
10task my_task;//<任务名>
//<端口及数据类型声明语句>
input a,b;
inout c;
output d,e'
//语句
c = foo1;
d = foo2;
e = foo3;
endtask任务调用:my_task(v,w,x,y,z);为何?
调用任务时的参数可以是已定义的参数,此时,v,w对应a,b即将定义好的参数传入模块,x,y,z对应c,d,e,将任务的输出结果传给定义好的参数。
5.2.3 function说明语句
1 | function [7:0] getbyte; //返回值的类型或范围 函数名——这一点和java的函数声明类似 |
嗯。。和软件的方法定义一般无二,唯独返回值的变量名无需定义,直接是函数名这点需注意
1 | //其定义还可以写错c语言形式 |
- 函数的定义蕴含声明了与函数同名的,函数内部的寄存器,若未定义类型和范围,则寄存器默认是1位。
- 函数的调用:result = control ? {getbyte(msbyte) , getbyte(lsbyte)} : 0
- 使用函数的约束条件
- 其定义不能包含任何的时间控制语句,即#,@,wait来标识的语句。
- 函数不能启动任务
- 定义函数时至少要一个输入参量
- 必须给与函数同名的一个变量赋结果值
5.2.4 函数的特殊用法
递归函数
verilog中的函数不能进行递归调用,设计时若某函数在两个不同的地方被同时并发调用,操作的是同一块地址空间。
通过使用automatic关键字即可以让函数成为自动的或可递归的。即仿真器为每一次函数调用动态分配新的地址空间。
嗯。。和软件也有些雷同
5.2.5 常量函数?
5.3 常用的系统任务
5.3.1 $diaplay 和 \$write任务
格式:$display(p1,p2,…pn); \$write(p1,p2,…pn);
这两个函数和系统任务的作用是用来输出信息,即将参数p2到pn按照参数p1的给定格式输出。
参数p1称为“控制格式”,参数p2至pn称为“输出表列”,区别在于display对应println,write对应print
- 输出格式控制:由双引号括起来的字符串,包含两部分
- 格式说明:由%和格式字符组成。作用是将输出的数据转换成指定的格式输出。格式说明总是由%字符开始。对于不同的数据用不同的格式输出
- 普通字符:换行符,制表符等

格式需注意的问题:
输出数据的显示宽度:
在$display中,输出列表中数据的显示宽度是自动按照输出格式进行调整的。总是用表达式的最大可能值所占的位数来显示表达式的当前值。
在用十进制数格式输出时,输出结果前面的0值用空格来代替。对于其他进制,输出结果前面的0仍然显示。
怎么能让这个位宽不显示呢?$display(“d = %0h a= %0h”, data,addr);
这样在显示输出数据时,在经过格式转换后,总是以最少的位数来显示表达式的当前值。
输出列表中包含不确定的值或高阻值
(1)十进制:
均为不定值:小写的x;
均为高阻值:小写的z;
部分位为不定值,大写的X;
部分位为高阻值,大写的Z;
(2)八和十六进制:换算成3位或4位二进制数为一组
1
2
3$display("%d",1'bx); //输出结果为x
$display("%h",14'bx0_1010) //输出结果为xxXa
$display("%h%o", 12'b001x_xx10_1x01,12'b001_xxx_101_x01); //输出结果为XXX1x5X
5.3.2 文件输出$fopen
verilog的结果通常输出到标准输出和文件。
打开文件:文件可以用系统任务$fopen打开。
用法:$fopen(“<文件名>”);
用法:<文件句柄> = $fopen<”<文件名>”>
任务$fopen返回一个被称为多通道描述符的32位值。多通道描述符中只有一位被设置为1。标准输出有一个多通道描述符,其最低位(第0位)置成1.标准输出也称为通道0.标准输出一直是开放的。以后对\$fopen的每一次调用打开一个新的通道,并且返回一个设置了第1位,第2位等,直到32位描述符的第30位。第31位是保留位。通道号与多通道描述符中被设置为1的位相对应。
多通道描述符的优点:可以有选择地同时写多个文件。——见下面的写文件部分
写文件:
系统任务$fdisplay, \$fmonitor, \$fwrite, \$fstrobe都用于写文件
以$fdisplay为例,用法为: \$fdisplay(<文件描述符> , p1,p2,p3,….pn);
1
2
3
4
5
6
7
8
9
10
11//例一:文件描述符
//多通道描述符
integer handle1,handle2,handle3;//整数是32位,这里定义的几个变量也就是通道描述符了
//标准输出是打开的
descriptor = 32'h0000_0001;
initial
begin
handle1 = $fopen("file1.out"); //handle1 = 32'h0000_0002
handle2 = $fopen("file2.out"); //handle1 = 32'h0000_0004
handle3 = $fopen("file3.out"); //handle1 = 32'h0000_0008
end但是!通道描述符不等于文件描述符!!
1
2
3
4
5
6
7
8
9
10
11//例二:写入文件
integer desc1,desc2,desc3;//3个文件描述符
initial
begin
desc1 = handle1 | 1;
$fdisplay(desc1, "Display1");//写到文件file1.out和标准输出stdout
desc2 = handle2 | handle1; //写到文件file1.out和file2.out
$fdisplay(desc2, "Display2");
desc3 = handle3; //写到文件file3.out
$fdisplay(desc3, "Display3");
end明显可以看出,通道描述符对应文件,而文件描述符可以对应一个或多个通道描述符,即可以操作多个文件
5.3.3 关闭文件$fclose
系统任务$fclose
用法:$fclose(<文件描述符>); eg: \$fclose(handle);
注意;文件一旦被关闭就无法再写入。多通道描述符中的相应位被置为0。下一次调用可以重用这一位。
5.3.4 显示层次
在显示任务中的输出格式中提到的%m
在模块中写入打印语句,且语句格式中添加%m,当模块进行多次的嵌套调用时把这个模块放入其中,就可以显示从最顶层模块名到该层模块名的层次。包括模块实例,任务,函数和命名块。
5.3.5 选通显示$strobe
系统任务 $strobe
和display的功能基本一样,都是打印显示,区别在于display与和其在一个时间单位开始的任务执行顺序不确定,但使用$strobe就可以等到同时刻的其他赋值语句执行完成后才执行。
即提供了一种同步机制(类似于线程同步),确保所有在同一时钟沿赋值的其他语句在执行完毕后才显示数据。
5.3.6 生成随机数$random
一般用法:$random%b, 其中b>0。给出另一个范围在(-b+1),(b-1)范围内的随机数。一般用于生成测试用随机脉冲序列。
6. 编译预处理
verilog允许在程序中使用几种特殊的命令(不是一般的语句)。编译系统通常会先对这些特殊的命令进行“预处理”,然后将处理结果和源程序一起进行通常的编译处理(类似于c语言的拼接机制先将包载入,拼接后再行编译)
预处理命令的符号:“`”
作用范围:定义命令之后到本文件结束或到其他命令定义代替该命令之处
6.1 宏定义`define
用一个指定的标识符(即名字)来表示一个字符串,一般形式为:
1 |
|
作用:用signal代替string这个字符串,编译预处理时用single替换所有string。
在编译预处理时将宏名替换为宏内容的过程称为“宏展开”。
需要注意的几点:
在引用已定义的宏名时,必须在宏名的前面加上符号“`”,表示该名字是一个经过宏定义的名字。
宏命名的意义不单是减少书写工作量,给某一变量赋以明确的意义;
比如`define WORDSIZE 8 ,然后以WORDSIZE定义寄存器位数,通过修改宏定义的常数即可以实现全部寄存器位数的修改!!
宏定义不是HDL语句,不必在行末加分号,如果加了分号会一起进行置换。
宏定义可以写在模块外,也可以写在模块内部。
6.2 文件包含处理`include
所谓“文件包含”处理是一个源文件可以将另外一个源文件的全部内容包含进来,即将另外的文件包含到本文件中,即导包
其一般形式为`include “文件名” 和c的导包关键字都一样
- 需要注意的几点:
- 一个`include命令只指定一个被包含的文件
- `include命令可以出现在源程序的任何地方,被包含文件名可以是相对或绝对路径名
- 多个include命令可以写在一行,后面可以跟空格和注释
6.3 时间尺度`timescale
格式:`timescale<时间单位>/<时间精度>
- 时间单位参量用来定义模块中仿真时间和延迟时间的基准单位
- 时间精度(取整精度):用来对延迟时间值进行取整操作
以1ns/1ps为例:时间值都是1ns的整数倍,模块中的延迟时间可表达为带3位小数的实数型。
verilog器件部分
锁存器
参考文章:综合器,我想要一个锁存器
提到锁存器和verilog设计的关系,第一个想法就是if_else条件判断和case条件分支没有对信号进行完全覆盖,即为语句中的所有变量赋值。
尝试用以下代码生成锁存器:
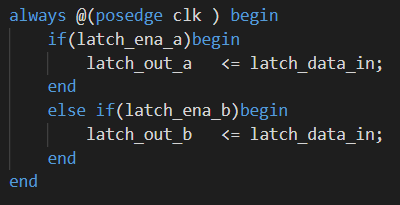
按照我的以前理解,out_a和out_b的值也是要由锁存器进行记录,但是事实貌似不是这样:
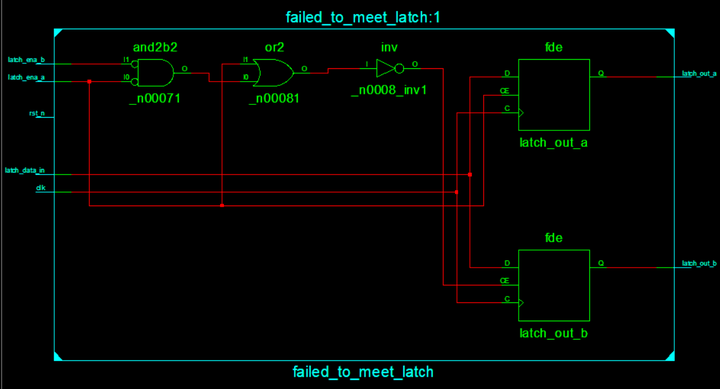
verilog实验部分
组合逻辑
1. 真值表
实际上就是由最小项构成的逻辑表达式对其进行描述

1 | module top_module( |
上述公式可以简单的用公式法或者卡诺图进行化简
2. Mt2015 q4
在已有module的基础上进行模块例化和连线,建立顶层module
mt2015_q4a:
1 | module mt2015_q4a (input x, input y, output z); |
mt2015_q4b:
1 | module mt2015_q4b ( input x, input y, output z ); |

1 | module top_module (input x, input y, output z); |
核心就是连线和端口连接
3. Ringer
最能体现硬件语言编写和软件语言编写思路上的差异:
ring输入1代表来电,此时震动模式vibrate_mode打开,则motor为1,否则ringer为1;注意ringer和motor在同一时刻只能有1个为1~

1 | module top_module ( |
软件:上来肯定是if-else顺序处理
硬件:真值表一画,齐活
4. n位输入中1的个数
模块为3位输入,两位输出
1 | module top_module( |
一种比较奇怪的直接写法:
1 | module top_module( |
- 通过异或的方式计算1的个数是奇数还是偶数,奇数out[0]为1,偶数时为0;
- 计算1的个数是否大于等于2,是,则out[1]为1;
for循环的使用:
1 | module top_module( |
注意这里需要对reg的初始值进行配置,且配置语句需要写在always块内!!!!!!!reg的默认值是x!!!
5. for循环
Gatesv100(always+for)
一个 100 位的输入向量[99:0] in。输出每一位和相邻位的关系:
- out_both:本输出向量的每一位应该指示对应的in的这一位和其左侧相邻位是“1”。例如,
out_both[98]应该表明in[98]和in[99]是否都为 1。由于in[99]左边没有,所以答案很明显,所以我们不需要知道out_both[99]。 - out_any:本输出向量的每一位应该指示对应的in的这一位或者其右侧相邻位是“1”。例如,
out_any[2]应该指示in[2]或in[1]是否为 1。由于in[0]右边没有邻居,答案很明显,所以我们不需要知道out_any[0]。 - out_different:本输出向量的每一位应该指示对应的in的这一位和其左侧相邻位不同。例如,
out_different[98]应该指示in[98]是否与in[99]不同。这里将向量视为环,因此in[99]左侧相邻位是in[0]。
1 | module top_module( |
Bcdadd100(generate+for)
该题是根据已经写好的十进制加法器(BCD one-digit adder)module来构建100位十进制加法器
BCD one-digit adder如下
1 | module bcd_fadd { |
使用的语法:generate
generate解析
generate是对parameter,module,assign,always等进行复制的操作,同时在内可以用genvar进行正整数的定义,供给循环使用,同时主要有三种类型
- generate_for
- generate_if
- generate_case
主要使用的是generate_for进行模块的复制
1 | module top_module( |
注意要把top_module的输出cout和寄存器的最后一位连接起来
即每一个4位加法器的cout连接到寄存器的一位,该寄存器值又被连接到下一个加法器的cin,最后一个cout的结果即module的输出cout
Mux256to1v(case分支)
输入较少的mux:
1 | 2选1Mux |
256 to 1 Mux:
题目: 创建一个1位宽的256:1多路复用器。256个输入全部打包为单个256位输入向量。sel = 0应该选择in [0],sel = 1选择in [1]中的位,sel = 2选择in [2]中的位,依此类推。
使用向量索引:
1 | module test ( |
1024 to 1 Mux:
题目: 创建一个4位宽的256:1多路复用器。1024个输入全部打包为256个4位输入向量。sel = 0应该选择in [3:0],sel = 1选择in [7:4]中的位,依此类推。
思维误区:
1 | module top_module( |
报错:Error (10734): Verilog HDL error at top_module.v(5): sel is not a constant File: /home/h/work/hdlbits.1564560/top_module.v Line: 5
sel不是常量报错;使用向量索引时的方法不对
解决:
1 | module top_module ( |
其他采用范围式的向量索引的写法:
1 | 法1 |
时序逻辑
1. 同步和异步复位
DFF with reset value (Dff8p)
复位信号高电平有效,时钟信号上升沿有效,8位输出的复位值为0x34.
1 | module top_module ( |
DFF with asynchronous reset (Dff8ar)
异步复位信号高电平有效,时钟信号上升沿有效,8位输出的复位值为0.
1 | module top_module ( |
如上,异步复位只需要将复位信号加入敏感值列表
2. DFF with byte enable(Dff16e)
本题中需要创建一个 16 路 D触发器。部分情况下,只需要多路触发器中的一部分触发器工作,此时可以通过 ena 使能端进行控制。使能端 ena 信号有效时,触发器在时钟上升沿工作。
byteena 使能信号以 byte 为单位管理 8 路触发器在时钟边沿触发与否。byteena [1] 作为 d[15:8] 高位字节的使能端,byteena [0] 则控制 d 的低位字节。
resetn 为同步,低电平有效复位信号。
所有的触发器在时钟上升沿被触发。
自己写的错误写法:
1 | module top_module ( |
正确写法:
区别于用assign进行连线,连线时需要对每一位进行赋值;
16个触发器用到哪个,在时钟上升沿时只对该触发器的输出进行更新,其他的保持不变。
1 | module top_module ( |
3. 组合逻辑D触发器
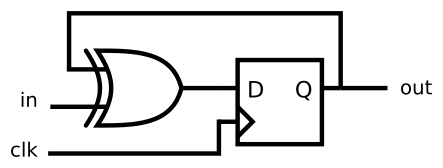
我的错误写法:
1 | module top_module ( |
报错:object out declared in a list of port declarations cannot be redeclared within the module body File: /home/h/work/hdlbits.1585378/top_module.v Line: 5
正确写法:
1 | module top_module ( |
尝试将out的声明reg给省去,结果也是正确的,估计是因为非阻塞的赋值语句本身就综合出了触发器,out被默认为寄存器类型

这里只需要单个触发器模块的输入输出关系
1 | module top_module ( |
4. 信号边沿检测
上升沿
输入信号发生从0到1的边沿跳变,在下一个时钟上升沿输出信号发生跳变~

- 输出由上升沿触发,判断上一拍过程中有没有发生边沿变化
- 每个时钟沿都要对输入信号进行存储,如果在当前周期in信号拉高,下一个有效沿能够检测到。
代码:
1 | module top_module ( |
上升沿和下降沿
1 | module top_module ( |
边沿捕捉寄存器

reset信号进行同步复位,对in的下升沿进行捕捉,置为1后结果保持不变
代码:
1 | module top_module ( |
双边沿触发器Dual-edge triggered flip-flop

边沿检测由原来的1个周期变为半个周期,因为FPGA没有双边沿触发,所以不接受@(posedge clk or negedge clk) 作为边沿触发
代码:
1 | module top_module ( |
理解:
a = b ^ c:一旦b或c发生翻转,则a一定发生翻转~
所以当最开始d从0发生翻转的时候,之后的clk上升沿对应的m一定发生翻转,此时输出值q发生翻转。
如果d保持,对于再过半个周期的clk下降沿来说,d和n的值都发生了翻转,m的值保持
如果d再次翻转,对于再过半个周期的clk下降沿来说,只有n的值都发生了翻转,m的值翻转,此时q的值也再次翻转