完成了SV和UVM的学习,也算是初出茅庐了。这篇文章主要是对行业的一些知识进行总结归纳,逐步提升自己对于行业的理解,用一个更高的视角来看待这份工作
IC验证的流程
AMBA标准接口
AMBA概述
什么是AMBA(Advanced Microcontroller Bus Architecture)片上总线?
随着深亚微米工艺技术日益成熟,集成电路芯片的规模越来越大。数字IC从基于时序驱动的设计方法,发展到基于IP复用的设计方法,并在SOC设计中得到了广泛应用。在基于IP复用的SoC设计中,片上总线设计是最关键的问题。为此,业界出现了很多片上总线标准。其中,由ARM公司推出的AMBA片内总线受到了广大IP开发商和SoC系统集成者的青睐,已成为一种流行的工业标准片上结构。AMBA规范主要包括了AHB(Advanced High performance Bus)系统总线和APB(Advanced Peripheral Bus)外围总线。
AMBA高级处理器总线架构,不同的速率需求构成了为高性能SoC设计的通信标准:
- AHB(advanced high-performance bus)高级高性能总线
- APB(advanced peripheral bus)高级外围总线
- AXI(advanced eXtension interface)高级可拓展接口
1995 - AMBA1.0 定义了APB外设总线以及ASB系统总线
1999 - AMBA2.0 定义了AHB - Advanced High-performance Bus, APB总线升级为同步总线
2003 - AMBA3.0 发布了高性能互联协议AXI, 以及APB总线扩展, AHB-Lite协议等
以及后来发布的AMBA4.0, AMBA5.0 协议, 定义了更多的总线及扩展。
具体可参考arm官网
AHB
AHB主要是针对高效率、高频宽以及快速系统模块所设计的总线,它可以连接如微处理器、芯片上或者芯片外的内存模块和DMA等高效率模块。
APB
APB主要用在低速且低功率的外围,可针对外围设备作功率消耗以及复杂接口的最佳化。APB在AHB和低带宽的外围设备之间提供了通信的桥梁,所以APB是AHB的二级拓展总线。如利用apb连接各种低速外设/外围控制器。如uart, i2c, sdio, i2s, pwm, timer, efuse, spi等等。
AXI
AXI 为AMBA3.0引入的总线协议, AXI高速度、高带宽,管道化互联,单向通道,只需要首地址,读写并行,支持乱序,支持非对齐操作,有效支持初始延迟较高的外设,连线非常多。
相比AHB有更多的优势, 故现在SOC设计中有取代AHB的趋势。
可直接连接ddr controller, usb controller, dma controller, sram, gic, AES加解密芯片等等, 也可以利用axi bridage连接apb总线, 利用apb连接各种低速外设/外围控制器。如uart, i2c, sdio, i2s, pwm, timer, efuse, spi等等。

AHB接口
AHB的组成
- Master:能够发起读写操作,提供地址和控制信号,同一时间只有1个Master会被激活。
- Slave:在给定的地址范围内对读写操作作响应,并对Master返回成功、失败或者等待状态。
- Arbiter:负责保证总线上一次只有1个Master在工作。仲裁协议是规定的,但是仲裁算法可以根据应用决定。
- Decoder:负责对地址进行解码,并提供片选信号到各Slave。每个AHB都需要1个仲裁器和1个中央解码器。

AHB基本信号
- HADDR:32位系统地址总线。
- HTRANS:M指示传输状态,NONSEQ、SEQ、IDLE、BUSY。
- HWRITE:传输方向1-写,0-读。
- HSIZE:传输单位。
- HBURST:传输的burst类型,SINGLE、INCR、WRAP4、INCR4。
- HWDATA:写数据总线,从M写到S。
- HREADY:S应答M是否读写操作传输完成,1-传输完成,0-需延长传输周期。
- HRESP:S应答当前传输状态,OKAY、ERROR、RETRY、SPLIT。
- HRDATA:读数据总线,从S读到M。
AHB基本传输
- 两个阶段。
- 地址周期(AP),只有一个周期。
- 数据周期(DP),由HREADY信号决定需要几个周期。
- 流水线传送。
- 先是地址周期,然后是数据周期。
等待传输状态:
HREADY信号拉高才能读写数据
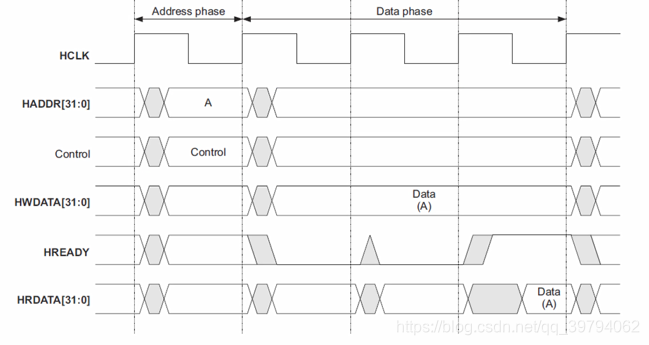
AHB transfer传输:
将上图的Control信号展开为HTRANS信号和HBURST信号。HBURST设置为INCR,即地址连续增长。NONSEQ指的是连续发送数据中的第一个数据,而SEQ指的是传输过程里面的数据。BUSY指的是虽然准备发送数据,而且是在发送数据过程里面,但是还没有准备好当前的这个数据,所以要等待下一拍才发送数据,因此就出现了两次0x24这个地址。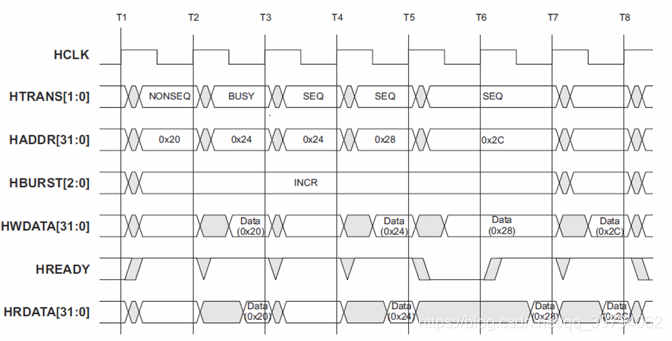
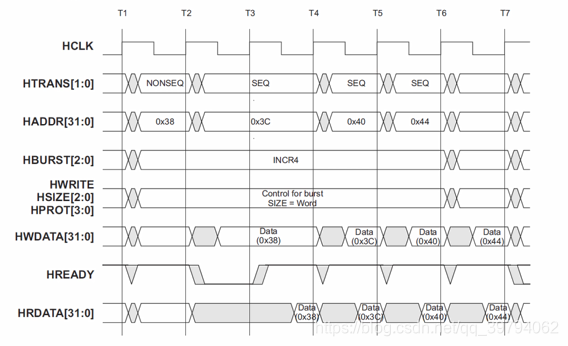
AHB burst传输:
HBURST信号设置为INCR4,表示连续发送4个数据。
APB接口
- 主要应用在低带宽的外设上,如UART、I2C,它的架构不像AHB总线是多主设备的架构。
- APB总线的唯一主设备是APB桥(与AXI或APB相连),因此不需要仲裁一些request/grant信号。
- APB的协议也十分简单,甚至不是流水的操作,固定两个时钟周期完成一次读或写的操作。
- 其特性包括:两个时钟周期传输,无需等待周期和回应信号,控制逻辑简单,只有四个控制信号。
APB时序协议的状态机
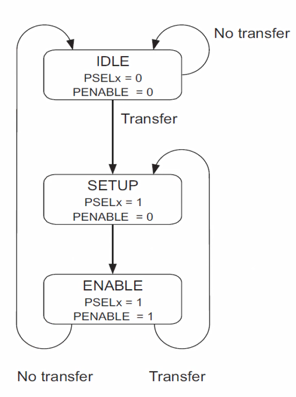
idle 状态
系统初始化为IDLE状态,此时没有传输操作,也没有选中任何从模块。当有传输要进行时,PSELx=1,PENABLE=0,系统进入SETUP状态,并只会在SETUP状态停留一个周期。当PCLK的下一个上升沿到来时,系统进入ENABLE状态。系统进入ENABLE状态时,维持之前在SETUP状态的PADDR、PSEL、PWRITE不变,并将PENABLE置为1。传输也只会在ENABLE状态维持一个周期,在经过SETUP与ENABLE状态之后就已完成。之后如果没有传输要进行,就进入IDLE状态等待,如果有连续的传输,则进入SETUP状态。
写操作
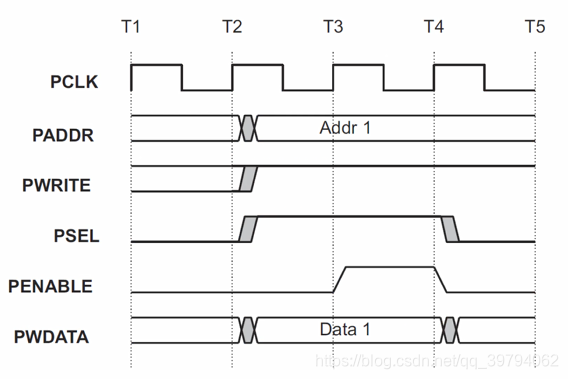
- 写操作发生时,伴随着地址线、写数据线、写信号线以及选择线一同变化。
- 写操作的第一个周期称之为SETUP周期。
- 写一个周期,PENABLE信号线置起,这表示ENABLE周期。
- 在ENABLE周期,地址线、数据线和控制线都应该保持有效。
- 在ENABLE周期结束后,本次写操作结束。
- PENABLE在写操作周期结束后,会同PSEL一同拉低,除非又需要立即跟随下一次传输。
- 为了省电,地址信号和写信号在一次传输过后不会改变,直到下一次传输发生。
读操作

- 地址线,写信号线、选择线将同写操作时一样保持不变。
- 从端需要在
ENABLE周期内,返回PRDATA。 PRDATA将在ENABLE周期的下一个周期被采样。
验证IP模板
1. 概念
什么是验证IP?
验证IP被用来植入到验证平台中,用来检查协议操作和接口。大多数标准协议和总线IP可以帮助检查基本的特性,例如系统启动,而VIP会做更多细致的检查。VIP的细致要求对于SoC复杂度增长所带来的验证困境相当重要。VIP可以在设计阶段的不同流程中充分应用。一个项目中,可以采取来自于不同提供商的VIP,共同构成一个完整的验证环境。
2. VIP的应用优势
- 如上图粉色区域所示,可以用一个USB3.0 VIP来代替一个总线以及一个外设,降低仿真资源。
- VIP可以在模块级(标准接口多)和子系统,系统级阶段进行使用。
- 利用VIP代替设计中的processor或者mem,降低动态仿真资源,提高效率。
在大趋势SoC的技术换代,验证人员对PCIe、USB、DDR、以及AMBA总线标准的理解尤其重要!多做项目,啃标准。

device VIP的使用

3. 如何使用VIP?
- 在开发SoC过程中,验证将占比超过一半的时间和人力,一个重要的原因就是层出不穷、多样化、不断升级的I/O组件。
- DDR存储接口也由于它在SoC中占据的比例增大,以及近年来为了解决功耗和延时问题所带来的新的复杂度。
- 在原有验证语言(e、C、Vera、SV)中,都存在其对应的VIP,支持一些定向测试和随机测试。
- 在后来的VMM、OVM以及UVM中,VIP的开发进一步地缩短了验证时间。
4. VIP的选择
- 仿真器提供商是否有对应的VIP,其协议版本是否与设计协议版本相匹配。
- 能否与其他公司的VIP兼容
- VIP的成熟度,如它之前的客户数量,以及是否经过了多次的silicon proven的开发周期。
- VIP的复杂度,编译和环境植入的难易度会直接影响验证的周期。
- 是否能够查阅丰富的文档以及得到及时的技术支持。
VIP的开发和发布
面临的3个问题
- 1/3的时间都是在进行验证环境的构建,有没有可能做到验证环境的自动化
- 市面的开源框架只能做到验证框架的自动化,做不到标准化的验证VIP的自动填充
- 验证环境构建起来了,添加用例之后,怎么把回归测试跑完,怎么收集功能覆盖率,再反过来更新测试用例
1. 概述
- 对于会被经常复用的总线协议或者功能模块,可以针对其开发专用的验证IP(VIP)。
- 对于总线VIP,需要master agent和slave agent,有时也需要Environment去构建多个主端对从端的验证环境。
- VIP也需要对应的配置对象,即configuration object,同时也需要对应的接口。
2. 主要的开发阶段
阶段1(定义)
- 功能特性提取
- 特性覆盖率创建及映射
- VIP的架构
阶段2(VIP基本搭建)
- driver、sequencer、monitor的少量实现(30%)
- 实现基本上的端到端的sequence
阶段3(完成monitor与scoreboard)
- 完成monitor —— 100%实现(checkers,assertions)
- 完成scoreboard —— 100%实现(数据完整性检查)
- 在monitor中,完成监测到的transaction与function coverage实现映射。
- 为映射更多的基本功能覆盖率,创建其它sequences。
阶段4(扩充test和sequence阶段)
- 实现更多sequences,从而获得80%的功能覆盖率。
阶段5(完成标准)
- sequence最终可以实现100%的功能覆盖率。
- 回归测试结果和最终的总结报告。
3. 验证方法
验证自己写的AHB的master agent和slave agent都没有问题,但是没有办法保证master或者slave都正确。如何验证自己写的VIP呢?
引入成熟的VIP放入到验证环境里面,类似于做反向。

把成熟的VIP的Master和自己的AHB的slave设置为Passive模式,连接两个验证模块。这样AHB的Master可以访问成熟的VIP的Slave,同时原有的test sequence library可以复用到AHB上面。这样就实现了用成熟VIP的测试序列去验证自己想要的Master。Passive模式下的Master可以monitor总线,也可以收集总线上的覆盖率,所以通过成熟的VIP的test和coverage来验证AHB的Master VIP。
接下来同样的道理,把成熟的Slave VIP和AHB的Master VIP设置为Passive模式,这样就可以使用成熟的test和coverage来验证AHB的Slave VIP。

最后把成熟的Master VIP和Slave VIP都设置为Passive模式,相当于把整个成熟环境都Passive掉,因为AHB的Master和Slave通过上面的方法都得到了验证,所以就可以进行AHB的Master对AHB的Slave的验证了。

VIP的发布
主要内容
VIP的源代码(可以选择加密,或者保留接口函数)
- active模式包括:driver,sequencer和tests。
- passive模式包括:monitor,用来做协议检查的assertion,接口的function coverage model。
特性列表以及对应的覆盖率列表
明确我支持或者不支持协议的哪些特性
- 保证与标准协议文档的主要特性对应。
- 与对应组件的测试,功能覆盖点,协议assertion和scoreboard检查。
VIP文档
- VIP的结构(在集成VIP的时候要理解各个子环境中的关联),具体的设计,用户指南(如何编译文件,功能覆盖率是多少),安装指令和覆盖率报告。
运行环境
- 回归仿真步骤(文件、编译、仿真、结果)。
assertion
用来与设计功能和时序做比较的属性描述

规则:grant在request置起后的第二个周期拉起
断言的功能
- 检查设计内容
- 提高设计的可视度和调试能力
- 检查设计特性在验证中是否被覆盖
可读性好,因此可以用来服务于设计文档(断言的原则:越短越好)
用来检查算法模型的断言在形式验证(formal verification)中可以穷尽计算,找出可能的违例(violation)。
可以自由地打开和关闭
一小部分子集甚至可以用来综合或移植到emulation中,用来完成跨平台的移植!!
基于断言的验证方法学(ABV)
Assertion Based Verification(ABV)方法学会定义断言
如何被使用:
- 谁写断言?
- 哪种语言用来写断言(抽象概念,和语言无关)
- 断言可以写在哪里(design里面或外面)
- 可以使用哪些断言库library()
- 断言如何调试
- 如何使用形式验证工具
- 如何使用断言覆盖率
断言覆盖率
- 仿真工具可以报告断言覆盖率,来指示哪些断言没有被触发
- 帮助检查是否验证计划捕捉到了所有需要的覆盖率
- 断言覆盖率和功能覆盖率可以共同量化验证进度
类型划分
立即断言
- 非时序的
- 执行时如同过程语句
- 可以在initial/always过程块或task/function中使用
并行断言
- 时序性的
- 关键词property用来区分立即断言和并行断言
之所以称之为并行,是因为他们与设计模块一同并行执行
例:
Request-Grant协议描述:request拉高,在2个周期后,grant拉高,在1个周期后,request拉低,在1个周期后,grant拉低
1 | property req_grant_prop |
并行断言只会在时钟边沿激活,变量的值是采样到的值。

并行断言的执行阶段
有点像monitor,不过monitor通过时钟块获得接口信号,其采样是在时钟上升沿之前的1个ps(看自己定义)
assertion,property,sequence
assertion和property
- assertion直接包含一个property
1 | c_assert: assert property(@(posedge clk) not(a && b) |
- assertion可以清晰独立的声明property
1 | property request_2state; |
property内部可以有条件的关闭
这里的disable iff(rst);就是其开关
property和sequence
这里的SV的sequence只是用来描述一个或多个时钟周期内的时序,和UVM中的sequence没啥关系,它是property的基本构建模块,并经过组合来描述复杂的功能属性
1 | sequence s1; |
这里的|=>符号,就表示如果s1的序列发生,则判断s2的序列是否紧接着发生。
property一般就是对时序做判断,就是某一时序满足后看另一时序是否满足
1 | sequence s1; |
这里的中括号,就代表2-3拍以内
功能覆盖率中想要实现对时序的覆盖,最好交由assertion来做
sequence
用来提供下列的场景描述:
- 第一个时钟周期,第一个表达式成立
- 接下来在若干个时钟周期后,第二个表达式也成立
- 接下来的若干时钟周期,后续的表达式也成立。
sequence可以在哪些模块中声明
可以在module,interface,program,clocking块和package中声明
一般就放入interface
sequence可以提供形式参数,用来提高复用性
1 | sequence s20_1(data, en); |
- 蕴含(implication)操作符用来表示:如果property中左边的先行算子(antecedent)成立,那么property右边的后续算子(consequence)才会被计算
- 如果先行算子不成功,那么整个属性就默认地被认为成功,这叫做“空成功”(vacuous success)
- 蕴含结构只能用在属性定义中,不能在序列中使用。
- 蕴含可以分为两类:交叠蕴含(overlapped implication)和非交叠蕴含(non-overlapped implication)
|->:操作符号是交叠交错符号
- 如果条件满足,评估其后续算子序列
- 如果不满足,表现为空成功,不执行后续算子。

|=>:操作符号是非交叠交错符号
- 如果条件满足,则在下一个周期评估其后续算子序列
- 如果不满足,表现为空成功,不执行后续算子。

property
结合sequence对时序和逻辑的描述,property可以用来描述设计的确切行为。
property可以在验证中用来做assumption,checker或者coverage:
- 当使用assert关键词时,可以用作checker来检查设计是否遵循property描述
- 当使用assume关键词时,可以作为环境的假设条件,对于仿真环境和形式验证均起到对激励进行假设的作用。
- 当使用cover关键词时,可以将property是否真正通过作为断言覆盖率来衡量
和sequence一样,可以在module,interface,program,clocking块和package中声明,注意:绝对不能在class里面做
可以同sequence一样具有形式参数
多种用途
sequene:只有当满足sequence条件时,property才通过
negation:即not property_expr。如果property_expr不满足,negation类的property才通过

disjunction(or):即property_expr1 or property_expr2,至少一个property_expr满足时,才能通过

conjuntion(and):通过or就知道了
if(expression)property_expr1 else property_expr2
implication蕴含,同sequence中用法一致,sequence_expr{|->, |=>} property_expr
instantiation 用法:即一个命名后的property可以在另一个property_expr中所使用

时钟声明
一般对于sequence或者property,默认情况下,在使用同一个时钟用来对数据做采样,但是也不排除多个时钟的采样情况
1 | @(posedge clk0) sig0 ##1 @(posedge clk1) sig1 |
这里的等一拍用的是前面的时钟

时钟的指定方式:
sequence中独立指定时钟:

在property中独立指定时钟

在过程块中,继承过程块的时钟

时钟块中,也可以继承时钟块的时钟

由此,断言的时钟由以下条件的优先级逐级判定:
- 显式声明的断言时钟
- 继承断言所嵌入环境的时钟
- 继承默认的时钟
对于并行断言,其必须具备时钟,即满足上述时钟条件之一
多时钟断言:必须显式声明时钟,无法继承或者使用默认时钟;
无法嵌套由时钟驱动的过程块语句
无法嵌套时钟块
property绑定

使用绑定的优势在于,无法修改原有设计代码,也无需添加监测信号,即可以实现断言的添加!
看一下之前的interface是如何连接到module的内部信号上的:
第一步:接口声明
1 | interface arb_intf(input clk, input rstn); |
第二步:接口例化+内部信号赋值
1 | arb_intf arb_if(.*); |

再来看一下绑定的方法和之前的方法有何区别


可以看到不存在赋值的操作,默认能看到module端口和内部一层的信号,但是还是完成了信号的监测
interface的例化默认在module的内部,模块什么时候例化不知道,但是只要模块被例化,interface就被例化。
也是因为这个原因,它只能进行监测且无法修改信号,所以对于用来添加property简直恰到好处
expect
之前的assert,assume,cover都是非阻塞方式,和仿真执行不影响。
expect是一种阻塞使用方式,会等待property执行通过才执行后续语句
简单来看,wait语句的地方,都可以用expect来实现

原式表示的是1个sequence,在200ms后的下一个时钟上升沿,分别对a,等一拍的b,再等一拍的c进行判断,判断成功后才能继续执行!!!
如图所示,蕴含操作符表示先等待a=1(从200ms开始,可能要等待多拍),等到之后再进入expect,如果后续b=1,c=1才能继续执行,哦负责就报错

assertion的检查和覆盖率的应用
APB总线协议的断言检查,APB协议中抽取出的部分协议要求
在PSEL为高时,PADDR总线不可以为X值
在PSEL拉高的下一个周期,PENABLE也应该拉高
- 在PENABLE拉高的下一个周期,PENABLE应该拉低
- 在PSEL和PWRITE同时保持为高的阶段,PWDATA需要保持

- 下一次传输开始前(如何判断下一次传播啥时候开始),PADDR和PWRITE信号应该保持不变
- 在PENABLE拉高的同一个周期,PRDATA应该发生变化
APB总线协议的断言覆盖率
- 写操作时,分别发生连续写(只需要覆盖到PSEL连续4拍为高,同时PWRITE连续4拍为高才能保证,PENABLE和PSEL的关系在上面的断言检查中已经检查过了 ,不用重复定义)和非连续写(PSEL信号每两拍就得拉下来至少1拍,PWRITE无所谓)
- 对同一个地址先做写操作,再不间隔做读操作
- 对同一个地址做连续两次写操作,再从中读取数据
- 读操作时,分别发生连续读和不连续读
- 发生对同一个地址的读操作再不间隔做写操作,再不间隔做读操作
总结
学完断言的相关内容能够做什么呢?
- 实现断言检查
- 实现断言覆盖率
- 断言覆盖率跟测试用例对应,测试用例又跟测试计划对应
- 用功能覆盖率定义上述时序过于复杂,可以用断言覆盖率,property+cover
收集合并最终的assertion检查结果的断言覆盖率,进行分析
从仿真结果检查哪些断言被触发且失败、哪些断言没有被触发、哪些断言的覆盖率满足或未满足
注意:仿真时要添加额外的仿真选项 -assertdebug -assertcover
设计描述信息标准化
IP-XACT是一种标准化、格式化的设计信息描述标准(IEEE 1685-2140)
IP-XACT定义了一种标准化方式去描述一个IP的关键信息,例如IP的用户可以从IP一致化信息中访问数据或实现设计的自动化
对于IP用户,当他们使用外部商业IP或者内部IP时,一般会得到大量从不同角度描述IP的文件,这包括RTL代码、使用文档、仿真模型、综合约束等。。
IP-XACT没有试图定义哪些内容需要提供,没有规范哪些内容需要组织
试图去定义一个电子版的数据手册,用来归档不同种类信息
IP-XACT标准最常用的场景:
- 定义IP模型的关键信息,例如顶层端口名
- 提供入口用来指引交付的IP文档所包含的不同信息
- 用来对由IP-XACT建模的IP提供配置信息和互联信息
想要完成自动化,就必须把所有信息都标准化,格式化出来
IP-XACT语言规范本身也建立在xml格式之上,所以IP-XACT标准本身阅读起来很吃力,因为其标准是对机器友好
因此,学习IP-XACT的重点在于如何使用而不是如何阅读,理解这种规范化设计数据文件的优点和用处。
与IP-XACT标准化设计信息类似的数据存储格式,还包括SystemRDL,XML,RALF,CSV,EXCEL等。
对于verifier的日常工作,我们需要面对的,可能是上述某一种标准化数据的存储格式,
我们需要理解不同的人利用这些数据可以实现和处理什么。
标准化往往就意味着可以更好的自动化!!!
IP-XACT基于XML格式,可以提供不同对象的描述信息:
- 组件(component):IP层次信息,包含IP参数,寄存器,端口,接口,信息层次较为抽象和宽泛
- 设计(design):包含层次化的设计信息,例如地址表,物理结构。组件和设计信息可以共同描述层次化IP的集成接口和内部结构
- 设计配置(design configuration):指的是针对具体的IP应用常见,基于设计IP-XACT文件,做出对应的设计配置,用来进一步决定设计实例的结构。一个设计文件可以对应多个设计配置文件。
- 总线定义(bus definition)和抽象级定义(abstraction definition):用来描述硬件的通信协议。
IP-XACT可以提供不同对象的描述信息:
生成器流程(generator chain):用来描述IP-XACT得以转化的流程:
例如生成哪一种工具或脚本,哪些参数,可以最终利用IP-XACT文件生成标准化文件。比如生成RTL代码,或者生成一些可读性文件,c的代码,sv的代码等等
可以看出IP-XACT不仅能实现寄存器信息,还包括设计的:
- 层次信息
- 总线信息
- 互联信息
- 配置信息
- 地址信息
- 集成信息等
理论上,通过IP-XACT管理的IP,可以实现开发,交付,集成和维护的标准化
寄存器模型自动化
寄存器描述文件
概念
- 目前的数字设计可配置化程度高,满足了设计的灵活性和成本的降低
同时,配置化数字设计带来了成百上千的寄存器,这些寄存器在数字化设计流程中扮演者关键作用,因为它们是硬件和软件的接口
如同MCDF的寄存器模块,配置寄存器和状态寄存器构成了硬件的编程接口
对寄存器信息的细致安全管理可以提高设计交付的质量

在soc系统中,主要由处理器,功能模块,I/O模块,总线和互联网络构成
多数模块均可以由外部或内部完成寄存器访问
寄存器访问可以归结为总线和寄存器模块
总线的标准化,和寄存器信息的标准化使得在寄存器信息标准化管理和自动化实现变为了可能。


寄存器信息编辑
一些商业寄存器编辑器大致会包含以下内容:
- 寄存器块(register block)
- 寄存器(register)
- 寄存器域(register fileld)

- 不少公司可能会内部开发寄存器信息编辑器(可视化的或者文本处理的),然后再通过脚本、模板来实现设计自动化和验证自动化
- 对于verifier,我们将模拟实际场景,采用Excel这种标准化的数据存储方法,结合python脚本实现寄存器的自动化生成
自动化
核心要点
- 描述文件的内容
- 如何生成UVM寄存器
- 根据MCDF寄存器描述的更新来相应修改寄存器文件
- python脚本自动生成寄存器模型SV文件
- 看新生成的寄存器文件,与MCDF的寄存器描述进行参照对比,确保信息一致性
- 用现有的寄存器模型SV文件来替换原有的寄存器模型SV文件,完成编译
寄存器模型深度应用
寄存器的随机配置
- 先对寄存器做随机化
- 将一些必须指定的寄存器域做写操作
- 最后做寄存器模型的update
和之前通过write方法进行寄存器配置的区别:
- 所有寄存器的域值统一配置,一目了然
寄存器域值的前门获取
问题:寄存器模型不支持域值的前门读写,需要添加新的方法,实现寄存器域的读写
寄存器域值的变更想要通过前门访问进行修改,可以通过updata:
比如32位slv_id寄存器,想要对8位的slv1的域进行修改,此时m_design和m_mirror不同,通过update方法就可以将slv1的变化更新到dut实际值上
使用read和write进行域值修改就没那么容易了,这俩方法只能通过register进行前门访问,这就意味着必须先获取当前的寄存器的32位值(read),然后进行8位的slv1的修改,最后再把改完后的32位期望值写入dut的寄存器
性能分析
功能验证目前已不能充分验证芯片系统,与之而来的是性能验证(performance)和效能(power)验证
效能验证的两部分无论是UPF用来做电源域的模拟开关验证还是与能耗收集评估验证,均需要对应的EDA工具,且专业性较强
性能验证需要考虑到两部分环境:
- 提供性能验证的平台需要足够快,使得软件,固件代码可以在其之上运行
- 性能验证需要结合将来会运用的软件、固件代码,这指的是我们需要采用真实或者贴近实际用例的软件代码~~
- 用来做性能分析的平台不单包括simulator,还会在FPGA和emulator上进行,这是基于他们出色的仿真速度的考量
性能验证的目标:
- 对目标硬件发送大量的数据
- 在固定的周期中采集数据量并计算带宽
- 从数据的接收时间到数据的送出的延时计算
性能计算
以mcdf为例:
- 从monitor中收集transaction,并进行performance计算
- 对于MCDF的数据吞吐量计算,以channel所有通道的数据输入总和作为输入带宽,以formatter的数据输出为输出带宽。
- 通过标记输入数据和输出数据,对同一个数据包在MCDF的输入和输出计算其延时,作为performance的又一个标准~~